Das Wort »Git« ist zunächst nichts weiter als Britischer Jargon für »Schwachkopf« oder auch »Blödmann«. Das »Git«, mit dem wir uns im Rahmen dieses Artikels befassen, ist allerdings weder schwach noch blöd — ganz im Gegenteil. Git ist ein Open-Source-System zur Versionsverwaltung, welches im April 2005 von Linus Torvalds "erschaffen" wurde, um es zur Verwaltung des Linux-Kernel-Quellcodes einzusetzen. Torvalds begründete die groteske Namensgebung damit, dass er seine Projekte stets nach sich selbst benennen würde.
»I'm an egotistical bastard, and I name all myprojects after myself. First ›Linux‹, now ›git‹.«
— Linus Torvalds
Einige Monate später — im Juli 2005 — wurde die Betreuung des Git-Projekts dem Japaner Junio Hamano anvertraut, der das Projekt seitdem betreut. Obwohl das System ursprünglich nur zur Verwaltung des Kernel-Quellcodes von Linux gedacht war, breitete sich das Projekt schnell aus und wurde von zahlreichen anderen Linux-Projekten zur Quellcode-Verwaltung adaptiert. Seit einiger Zeit erlebt Git zudem auch außerhalb der Linux-Welt einen Aufwind und wurde durch grafische Benutzeroberflächen und entsprechenden Hosting-Diensten in gewissem Maße "gesellschaftsfähig".
Heute ist Git die "State of the Art"-Lösung zur Versionsverwaltung in der Softwareentwicklung (aber auch anderen Branchen) und wird daher auch zunehmend in Unternehmen eingesetzt. Dies ist mit großer Wahrscheinlichkeit auch der Grund, warum Sie diesen Artikel gerade lesen.
Was ist »Versionsverwaltung«?
Die klassische Versionsverwaltung ist primär aus der Softwareentwicklung bekannt, wo damit unterschiedliche Entwicklungsstände von Projekten gesichert und im Notfall wiederhergestellt werden können. Allerdings dient die Versionierung hierbei nicht nur der reinen Erstellung von Sicherungskopien der einzelnen Fortschritte, sondern auch, um dezentral und parallel in Teams an gemeinsamen Projekten entwickeln zu können. Hierbei fungiert die Versionsverwaltung dann also als zentrales Lager für den Quellcode (»Repository«), aus dem die einzelnen Entwickler den aktuellen Stand des Projekts beziehen können und in welches dann später auch die vorgenommenen Änderungen wieder eingespielt werden können.
Wo parallel und dezentral gearbeitet wird, kommt es natürlich zwangsweise zu Konflikten und Überschneidungen von Quellcode-Dateien und Teilen des Quellcodes in der selben Datei. Hierfür findet bei Systemen zur Versionsverwaltung eine Zusammenführung (»Merging«) der einzelnen Teile statt. Arbeiten also mehrere Entwickler an ein und derselben Datei, so sind Versionsverwaltungssysteme meist fähig, die jeweiligen Änderungen zu erkennen und im Repository zusammenzuführen — und sollte die automatische Zusammenführung nicht funktionieren (etwa weil identische Code-Zeilen bearbeitet wurden), kann der aufgetretene Konflikt von Hand aufgelöst werden.
Weitere wichtige Features in der Versionsverwaltung sind darüber hinaus Tags und Branches. Mit Tags können Entwicklungsstände wie bspw. Release-Versionen (v0.1, v0.2, … , v1.0, v1.1, …) gekennzeichnet werden, um später einfach auf diese zurückspringen zu können oder eine bestimmte Version wiederherzustellen. Branches ermöglichen dabei die Isolierung der dezentralen Entwicklung an ein und demselben Repository in verschiedene Zweige. Sie werden daher benutzt, um verschiedene Funktionen voneinander isoliert zu entwickeln. Der Master-Branch ist dabei der "Standard"-Branch und repräsentiert oftmals die laufende, stabile Live-Version (oft auch »Production-Version« genannt) und für Änderungen zweigen die Entwickler von diesem in Form eines eigenen Branches ab, entwickeln in diesem Branch und führen nach Abschluss der Arbeiten diesen eigenen Branch und den Master-Branch wieder zusammen.
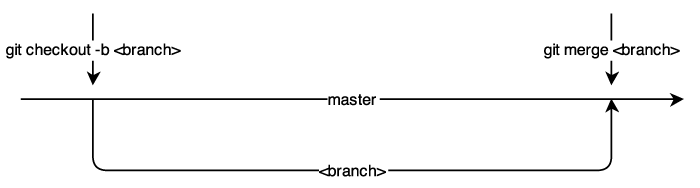
Unter dem Punkt 'Best Practices' wird im Laufe dieses Artikels nochmals detaillierter auf das Branching eingegangen.
Git ist dabei bei Weitem nicht das einzige System zur Versionskontrolle: Weitere bekannte und populäre Systeme sind »CVS« sowie dessen Nachfolger »SVN«. Zwei große Besonderheiten, die Git mit sich bringt, sind dessen Effizienz und Geschwindigkeit — auch bei großen Projekten mit langen Projekt-Geschichten. Zudem benötigt Git dabei keinen zentralen Projekt-Server, auf dem gearbeitet wird. Oft existiert jedoch ein zentraler Server (»Remote«), auf den alle Entwickler nach Abschluss ihrer Arbeiten pushen. Dabei lädt jeder Entwickler das vollständige Projekt (inkl. seiner vollständigen Historie) vom Remote-Repository in seine lokale Umgebung (»Working Copy«) — durch diesen dezentralen Ansatz ist eine Ausfallsicherheit des Entwicklungsverlaufs gewährleistet, da jeder Entwickler auch bei Ausfall des zentralen Repositories stets über das gesamte Projekt verfügt und keine Unterscheidung zwischen lokalen und entfernten Entwicklungszweigen stattfindet. Dieser fehlende Zwang einer zentralen Instanz ermöglicht es zudem, ausschließlich für sich selbst lokal auf dem eigenen Mac zu arbeiten. Der initiale Installations- und Konfigurationsaufwand, um Git zu nutzen, ist dabei kurz und schmerzlos.
Installation
Git ist bereits Teil jeder Installation von Mac OS X und muss daher nicht gesondert nachinstalliert werden. Welche Git-Version installiert ist, kann mit folgendem Befehl im Terminal (befindet sich im Programm-Ordner "Dienstprogramme") ausfindig gemacht werden.
git --version
Konfiguration
Zunächst müssen Name und E-Mail-Adresse des Entwicklers angegeben werden. Diese Angaben werden als Autor-Angaben für Commits verwendet und sollen dazu dienen, den Entwickler zu identifizieren.
git config --global user.name "Moritz Macintosh"
git config --global user.email moritz@icloud.com
Die Konfiguration wird dabei global in der Datei .gitconfig im Home-Verzeichnis des Benutzers abgelegt. Dort kann sie überprüft und/oder manuell editiert werden.
Befehle
Die folgenden Befehle repräsentieren das grundlegende Werkzeug für den Einstieg in Git. Da sich dieser Artikel mit dem Einstieg in die Versionsverwaltung mit Git beschäftigt, wird nur auf die für den Start relevanten Befehle und Parameter eingegangen.
Erstellen / Klonen
Neues Repository anlegen
Erstellt ein neues Repository in dem Ordner, in dem der Befehl aufgerufen wurde.
git init
Lokales Repository klonen
git clone /pfad/zum/repository
Remote-Repository klonen
git clone username@host:/pfad/zum/repository
Hinzufügen / Entfernen
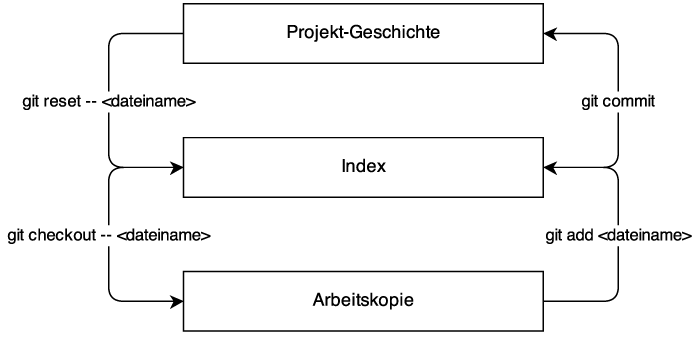
Ein Repository besteht prinzipiell aus 3 "Instanzen". Die erste ist die eigene Arbeitskopie (»Working Copy«), die die "echten" Dateien enthält. Die zweite ist der Index, der als eine Art Zwischenstufe (»Staging«) agiert. Die dritte ist der HEAD, der auf den letzten Commit zeigt. Änderungen wandern dabei schrittweise von der ersten bis zur dritten Instanz: Sie werden zunächst in den Dateien in der Arbeitskopie vorgenommen, werden dann über die folgenden Befehle dem Index hinzugefügt und schließlich in Form eines Commits zum HEAD der Projekt-Geschichte.
Änderungen an einzelner Datei dem Index hinzufügen
git add <dateiname>
Alle Änderungen an Dateien dem Index hinzufügen
git add .
Entfernen von Dateien aus dem Index
git rm --cached <dateiname>
Status anzeigen
Zeigt veränderte Dateien im Working-Tree an.
git status
Commit & Synchronisieren
Sind die gewünschten Änderungen dem Index hinzugefügt, werden diese in Form von Commits bestätigend freigeschaltet — also "fix" gemacht.
Änderungen commiten
git commit -am "Commit message"
Commits auf Remote-Repository pushen
Nach dem Commit befinden sich die Änderungen im HEAD, aber noch nicht im entfernten Repository. Daher müssen Commits dann noch gepusht werden.
git push origin master
master ist hierbei der Branch, der gepusht werden soll.
Remote-Repositories anzeigen
git remote -v
Remote-Repository zum lokalen Repository hinzufügen
Wurde ein Repository nicht von einem Remote geklont, soll später aber dorthin gepusht werden, können beliebig viele Remote-Repositories hinzugefügt werden.
git remote add origin <server>
Remote-Repository ersetzen
git remote set-url origin <server>
Branches
Neuen Branch anlegen und dorthin wechseln
git checkout -b <branch>
Zu Branch wechseln
git checkout <branch>
Zu Master-Branch zurückwechseln
git checkout master
Branch löschen
git branch -d <branch>
Lokalen Branch in das Remote-Repository pushen
gut push origin <branch>
Updating
In der Entwicklung in Teams ist es selbsterklärend wichtig, dass jeder Entwickler selbst seine vorgenommenen Änderungen pusht, sondern auch, dass alle Entwickler diese Änderungen untereinander abgleichen.
Lokales Repository auf Änderungen am Remote-Repository aktualisieren
git pull
Mit einem Pull werden dabei eigentlich zwei Befehle ausgeführt: Fetching, bei dem die Änderungen zunächst heruntergeladen aber noch nicht angewandt werden, und Merging, bei dem heruntergeladene Änderungen auf den lokalen Stand angewandt werden.
Merging
Änderungen von anderem Branch mergen
git merge <branch>
Änderungen/Unterschiede zwischen zwei Branches einsehen
git diff <quell_branch> <ziel_branch>
Tagging
Tag erstellen
git tag <tag> <commit_id>
Commit-IDs anzeigen
git log
Restore
Datei der Arbeitskopie durch die letzte aus dem HEAD ersetzen
git checkout -- <dateiname>
Änderungen, die bereits dem Index hinzugefügt wurden, bleiben bestehen.
Arbeitskopie vollständig zurücksetzen
Um lokale Änderungen vollständig zu entfernen, kann der letzte Stand vom Remote bezogen werden.
git fetch origin
git reset --hard origin/master
Tagging
Tag setzen
Tags werden auf Commits gesetzt, die dann den letzten Commit unter dem entsprechenden Tag (also der Version, wenn Tags für Release-Versionen verwendet werden) darstellen. Diese werden dabei über ihre Commit-ID angesprochen. Es ist möglich, die Commit-ID zu kürzen, solange diese noch eindeutig ist. In der Regel werden — sofern möglich — die ersten 10 Zeichen der Commit-ID verwendet.
git tag 1.2.3 3f09db07b3
Liste aller Tags anzeigen
git tag -l
Commits eines bestimmten Tags anzeigen
git show 1.2.3
.gitignore
In beinahe jedem Projekt existieren Dateien und Ordner, die nicht in ein Repository übernommen werden müssen oder sollen — etwa Cache-Ordner. Hierfür wird im gewünschten Repository eine Datei namens .gitignore angelegt und dort die entsprechenden Regeln eingepflegt. Meist gibt es keine allgemeingültige .gitignore-Datei, da sich die auszuschließenden Dateien von Projekt zu Projekt unterscheiden. Ein einfaches Beispiel könnte wie folgt aussehen.
# Einzelne Datei ausschließen
.DS_Store
# Ordner ausschließen
build
# Einzelne Datei in Ordner ausschließen
src/main.less
# Wildcards
*.zip
Zudem besteht die Möglichkeit, eine globale .gitignore-Datei anzulegen. Darin enthaltene Regeln werden dann für alle Git-Repositories angewandt. Diese Datei wird in der Regel im Home-Verzeichnis des aktuellen Benutzers unter ~/.gitignore_global abgespeichert und mit folgendem Befehl aktiviert.
git config --global core.excludesfile ~/.gitignore_global
Änderungen in .gitignore werden ignoriert?
Wurden Änderungen an der .gitignore-Datei getätigt, diese aber ignoriert, so muss der Git-Cache mit folgendem Befehl geleert werden. Keine Sorge: Dabei werden die Dateien nicht auf dem Dateisystem gelöscht, sondern lediglich aus dem Tracking-Cache von Git.
git rm -r --cached .
Anschließend werden wieder alle Änderungen dem Index hinzugefügt — nun wird die .gitignore-Datei allerdings korrekt angewandt — und commited.
git add .
git commit -m "Nun funktioniert die .gitignore-Datei wieder korrekt."
Übersicht
Die folgende Grafik resümiert nochmals die grundlegenden Befehle und die Instanzen Arbeitskopie, Index sowie die Projekt-Geschichte.
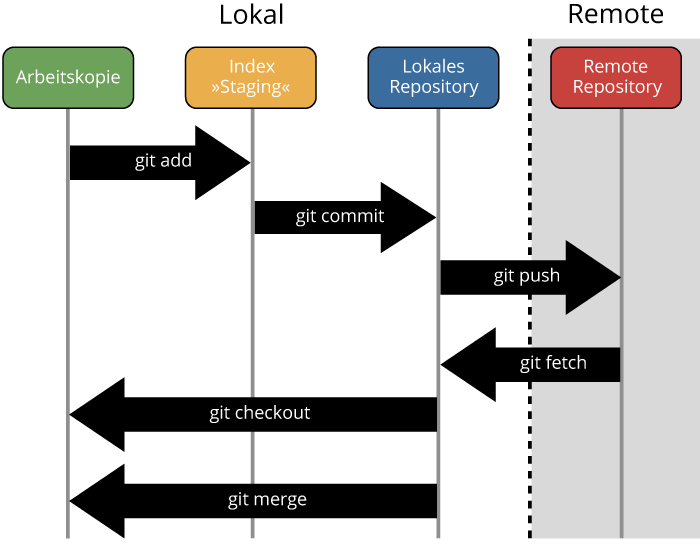
Zusätzlich visualisiert das folgende Zustandsdiagramm nochmals die verschiedenen Zustände von Änderungen und die grundlegenden Befehle hierbei.
Tools / GUIs
Wer sich im Terminal und mit obigen Befehlen eher unwohl fühlt, der kann auf Tools und GUIs für die Arbeit mit Git zurückgreifen. Meine persönliche Empfehlung ist hierbei »SourceTree« von Atlassian, das neben Mac OS X auch für Windows erhältlich ist.
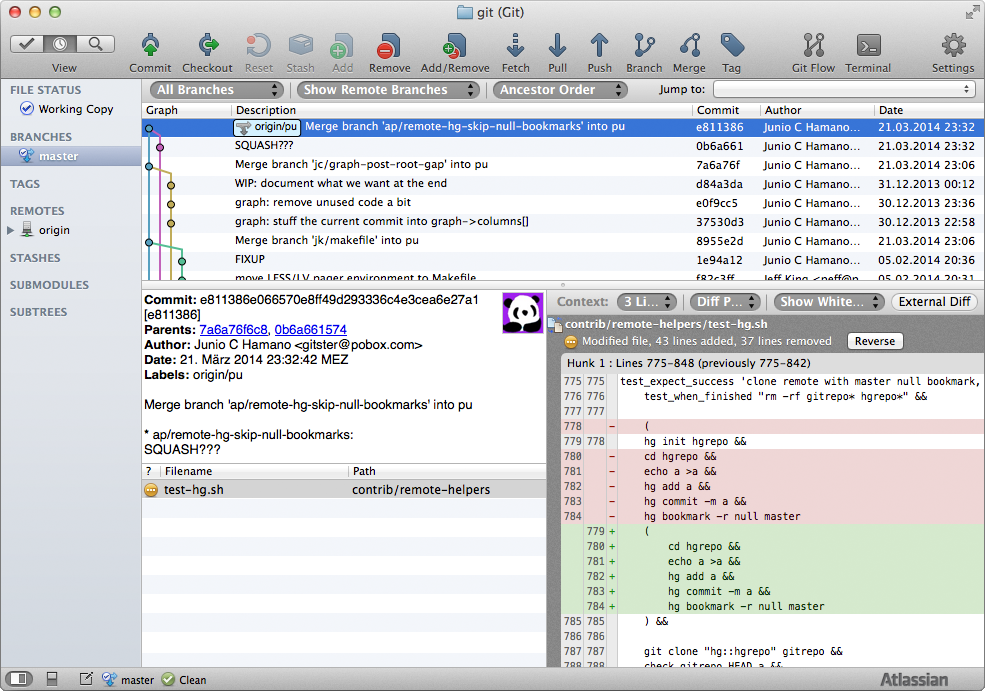
Dabei hat Atlassian das Rad nicht neu erfunden, aber die Einstiegshürde zur Arbeit zum Git stark reduziert. SourceTree bietet kein zentrales Killer-Feature, sondern diverse Kleinigkeiten, die die tägliche Arbeit mit Git vereinfachen.
Neben SourceTree existieren noch folgende Tools bzw. GUIs für die Arbeit Git unter Mac OS X.
Best Practices
Branches verwenden
Branches sind eine der mächtigsten und wichtigsten Funktionen von Git — und das nicht ohne Grund: Das schnelle und einfache Erstellen von (parallelen) Zweigen in der Entwicklung war von Anfang an eines der zentralen Anforderungen. Sie vermeiden Chaos und gegenseitiges Überschreiben von Code während der parallelen Entwicklung. Für jedes neue Feature, jeden Bugfix und jede Idee sollte daher ein neuer, eigenständiger Branch erstellt werden, in dem das Feature, der Bugfix oder die Idee ausprogrammiert wird und nach Abschluss in den Master gemergt wird.
Dabei wird zu keinem Zeitpunkt im Master-Branch selbst entwickelt und herumprobiert. Der Master-Branch bleibt sauber und stellt die Production-Version dar. Nach Abschluss eines Branches wird ein Pull-Request an den Verantwortlichen (meist der Leiter der Entwicklung eines Teams) geschickt und nur dieser merged den Branch in den Master. Jeglicher Push/Merge direkt in den Master-Branch wird kommentarlos reverted.
Verwandtes in Commits zusammenfassen
Ein Commit sollte die Hülle für verwandte und zusammengehörende Änderungen sein. Werden bspw. zwei unteschiedliche Bugs behoben, sollten die Änderungen in zwei unterschiedliche Commits, die jeweils einem Bug zugehörig sind, verpackt werden. So ist es leichter für andere Entwickler, Änderungen nachzuvollziehen und im Fehlerfall Rollbacks durchzuführen.
Änderungen vor jedem Commit testen
Ist eine Änderung ausprogrammiert, darf diese nicht blind in der Annahme, sie sei komplett, commitet werden. Jede Code-Anpassung muss zuvor gründlich getestet werden, um sicherzustellen, dass die Änderung auch wirklich vollständig abgeschlossen ist und keine unerwünschten Nebenwirkungen resultiert.
Gute Commit-Messages schreiben
Commits sollten mit einer kurzen Zusammenfassung der vorgenommenen Änderungen beginnen (~50 Zeichen als Orientierung). Zudem sollte angegeben werden, was die Motivation für die Änderung war (bspw. Angabe eines Tickets) und was sich von der bisherigen Implementierung unterscheidet. In der Formulierung sollte stets Imperativ Präsens verwendet werden (»change« statt »changed« oder »changes«), um die Konsistenz mit den vom Git-Merging-Tool erzeugten Messages zu wahren.
Commits möglichst oft erstellen
Das häufige Commiten von Änderungen hält die Commits klein sowie übersichtlich und ermöglicht es, Verwandtes zusammenzufassen. Darüber hinaus ermöglicht es, Änderungen am Code schneller und häufiger mit den anderen Entwicklern im selben Repository zu teilen. So lassen sich Änderungen schneller/besser einspielen und größere Merge-Conflicts vermeiden.
Keinen halbfertigen Code commiten
Nur abgeschlossener Code sollte commitet werden. Dies bedeutet nicht, dass ein großes Feature vollständig abgeschlossen werden muss, bevor die Änderungen commitet werden — das Gegenteil ist der Fall: Große Änderungen sollten in kleine und logische Einheiten unterteilt werden, die jeweils für sich abgeschlossen und commitet werden. Es macht aber keinen Sinn, am Ende des Tages halbfertigen Code zu commiten, nur damit der Feierabend guten Gewissens eingeleutet werden kann.
Sollte eine saubere Arbeitskopie nötig sein (etwa um einen frisch-aufgetauchten Bug zu beheben), sollten die bisherigen Arbeiten nicht einfach commitet werden, sondern durch die Stashing-Funktion von Git verwahrt werden. Ist der Zwischen-Bug behoben und commitet, können die vorherigen Änderungen wiederhergestellt werden.
Versionskontrolle ≠ Backup-System
Das eigene Repository in Form eines Remote-Repositories gesichert zu haben ist ein netter Seiteneffekt der Verwendung von Versionskontrolle während der Entwicklung. Allerdings sollte die Versionskontrolle nicht als klassisches Backup-System verstanden werden: Die Aufmerksamkeit sollte auf semantischen und durchdachten Commits liegen, nicht auf dem reinen Vollstopfen mit Dateien.